Security Auditing
Saving each event performed with Clutch for security auditing is a top-level concern, and the processes to accomplish this fit into the normal component architecture.
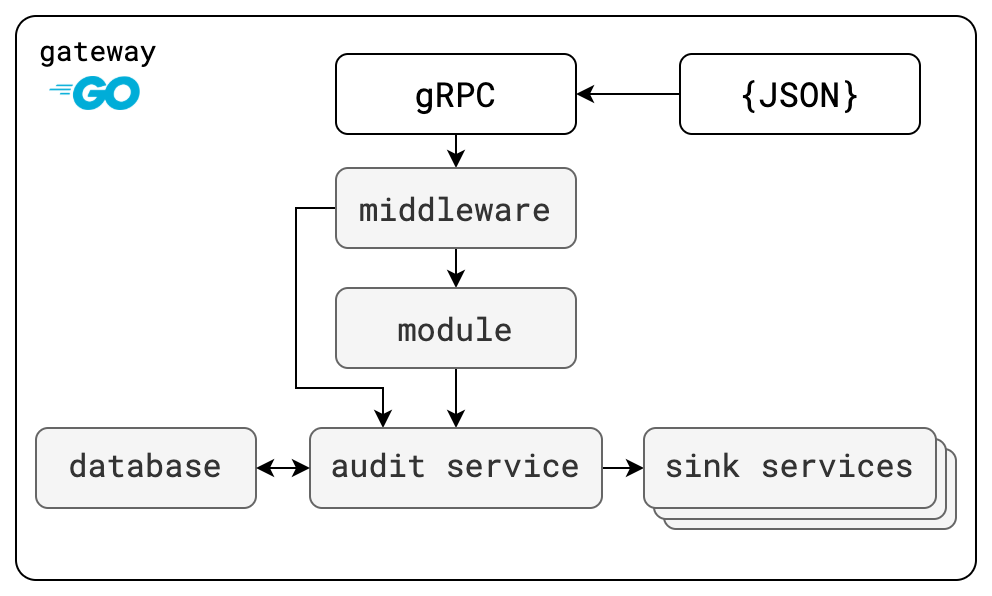
Clutch has configurable middleware to save data on each incoming request, a module to query for previous events, and services to store and forward events to new sinks. What information it stores for the request comes from API annotations on the request itself. The below table has the components ordered as they are in a call-chain.
| Component Name | Description |
|---|---|
clutch.module.audit | Module to retrieve audit events, called from outside of Clutch and calls the audit service. |
clutch.middleware.audit | Middleware that runs on each request. Calls the audit service to store request information. |
clutch.service.audit | Handler in front of storage services. Called to save or retrieve request information. |
clutch.service.audit.sink.* | Calls the audit service to retrieve request information. Call out of Clutch to forward the events. |
The annotations are read by middleware for each request and response, which forwards the information to the audit service for storage. The audit service is responsible for persistence as well as forwarding to other sinks to fan-out the messages. Each step of saving and forwarding is configurable with filters based on event attributes.
API Annotations
Clutch's auditing middleware reads the value of two API annotations: the request "type" to determine what sort of action is being performed on a resource, and the resource name to identify what item is being modified.
These annotations let customizable data on each request be logged and reviewed.
Action Types
Clutch will save the the "type" of action that was performed (create, read, update, or delete or CRUD operations) for each request. The request type comes from an API annotation on each RPC.
From the AmiiboAPI example proto, to show that the GetCharacters endpoint is a "read" operation, an extra option annotation would be needed.
syntax = "proto3";
package clutch.amiibo.v1;
option go_package = "github.com/{path_to_gateway}/backend/api/amiibo/v1;amiibov1";
import "google/api/annotations.proto";
import "api/v1/annotations.proto";
service AmiiboAPI {
rpc GetCharacters(GetCharactersRequest) returns (GetCharactersResponse) {
option (google.api.http) = {
post : "/v1/amiibo/getCharacters"
body : "*"
};
option (clutch.api.v1.action).type = READ;
}
}
The annotation would look similar for the other supported types of changes.
Resource Names
Clutch will also resolve what resources were modified by each request to their unique identifiers. This is also accomplished through API annotations.
There are two different annotations used to mark the resources in a single request:
- A
fieldsannotation will indicate what fields contain resource names. - A
patternsannotation will try template substitution with field values in order to create a name.
If we wanted to add these annotations to the Amiibo example, where the identifier for a character is a combination of its name and game series, we would make the following modifications to the API definition.
syntax = "proto3";
package clutch.amiibo.v1;
option go_package = "github.com/{path_to_gateway}/backend/api/amiibo/v1;amiibov1";
import "google/api/annotations.proto";
import "validate/validate.proto";
import "api/v1/annotations.proto";
service AmiiboAPI {
rpc GetCharacters(GetCharactersRequest) returns (GetCharactersResponse) {
option (google.api.http) = {
post : "/v1/amiibo/getCharacters"
body : "*"
};
option (clutch.api.v1.action).type = READ;
}
}
...
message GetCharactersResponse {
option (clutch.api.v1.id).fields = "characters";
repeated Character characters = 1;
}
message Character {
option (clutch.api.v1.id).patterns = {
type_url : "amiibo.v1.Character",
pattern : "{name}/{game_series}"
};
string name = 1;
string game_series = 2;
string amiibo_series = 3;
string image_url = 4;
enum Type {
UNSPECIFIED = 0;
CARD = 1;
FIGURE = 2;
YARN = 3;
}
Type type = 5;
}
The first annotation (fields = "characters") says that to get the set of resources contained in this message, to look at the characters field.
The second annotation (patterns = ...) says that the identifier for this message is built by combining the value of the name field with the value of the game_series field.
Middleware
On each request, the above annotations are read along with what endpoint was called, by whom, and when. When a response is being sent, any additional resources or final identifiers are merged with the initial list from the request.
All of this information is passed along to the audit service to persist.
The configuration for the audit middleware looks like:
gateway:
...
middleware:
...
- name: clutch.middleware.audit
...
Service
The audit service has two behaviors: write requests somewhere, and read them back out. It takes events from the middleware and saves them, and it also pushes them to later "sinks" for further processing.
Clutch ships with an implementation that uses Postgres as backing storage. With this, events that are saved can be filtered. At Lyft, we use this to prevent saving healthcheck information, since it is not interesting to us from a security perspective.
The configuration for this looks like:
...
services:
...
- name: clutch.service.db.postgres
typed_config:
"@type": types.google.com/clutch.config.service.db.postgres.v1.Config
connection:
host: ${DB_HOST}
port: ${DB_PORT}
user: ${DB_USER}
ssl_mode: DISABLE
dbname: clutch
- name: clutch.service.audit
typed_config:
"@type": types.google.com/clutch.config.service.audit.v1.Config
db_provider: clutch.service.db.postgres
sinks:
- clutch.service.audit.sink.slack
Module
Clutch's audit events can also be viewed by querying the audit module if it is enabled.
Example config
Local Adhoc Use
Clutch ships with an in-memory storage for events which allows it to be used without setting up a Postgres database. It is not recommended to run this way outside of a trial or adhoc temporary use. All history of actions taken with Clutch will be lost with the process shutting down.
gateway:
...
middleware:
...
- name: clutch.middleware.audit
...
services:
...
- name: clutch.service.audit.sink.logger
- name: clutch.service.audit
typed_config:
"@type": types.google.com/clutch.config.service.audit.v1.Config
in_memory: true
filter:
denylist: true
rules:
- field: METHOD
text: Healthcheck
sinks:
- clutch.service.audit.sink.slack
Recommended Production Setup
Below is sample configuration to show how the services described are enabled. Note that because services are instantiated in the order they are listed, order matters! Since the audit service depends on both the database and the sink, it needs to be listed after them.
gateway:
...
middleware:
...
- name: clutch.middleware.audit
...
services:
...
- name: clutch.service.db.postgres
typed_config:
"@type": types.google.com/clutch.config.service.db.postgres.v1.Config
connection:
host: ${DB_HOST}
port: ${DB_PORT}
user: ${DB_USER}
password: ${DB_PASSWORD}
ssl_mode: DISABLE
dbname: clutch
- name: clutch.service.audit.sink.logger
- name: clutch.service.audit
typed_config:
"@type": types.google.com/clutch.config.service.audit.v1.Config
db_provider: clutch.service.db.postgres
filter:
denylist: true
rules:
- field: METHOD
text: Healthcheck
sinks:
- clutch.service.audit.sink.slack
Sinks
Sinks asynchronously propagate events to other systems after they are persisted to Clutch's database.
Clutch ships with a logging sink as a scaffold for your own, as well as a sink for Slack.
Adding and customizing audit sinks lets you save or process infrastructure events however appropriate for your needs.
Slack Sink
By default, the Slack sink creates a formatted Slack message using a subset of information saved in an audit event. The default Slack message provides a summary, answering questions such as what operation was performed, who performed the operation, and what resources were operated on.

The Slack sink requires your Slack app’s bot token and the channel to post the messages. You can optionally provide filter rules to control what kinds of Slack audits are sent to the channel.
Example Config:
...
services:
...
- name: clutch.service.db.postgres
...
- name: clutch.service.auditsink.slack
typed_config:
"@type": types.google.com/clutch.config.service.auditsink.slack.v1.SlackConfig
token: <token>
channel: <channel>
filter:
rules:
- field: SERVICE
text: clutch.k8s.v1.K8sAPI
- name: clutch.service.audit
typed_config:
"@type": types.google.com/clutch.config.service.audit.v1.Config
db_provider: clutch.service.db.postgres
sinks:
- clutch.service.audit.sink.slack
Custom Slack Messages
A custom Slack message can be created for a given /service/method using the available metadata (the API request and response body) in an audit event. The custom message will then be appended to the default Slack message for a richer Slack audit.

Creating a Custom Slack Messages
The feature is powered by the Golang template package. In clutch-config, you can provide a template with the field names from the API request and/or response, which will be replaced with the field values at parse time. The template can also include Slack mrkdwn to add useful visual highlights to the custom message.
Creating the template:
.Request.<key_name>to obtain data from the API request.Response.<key_name>to obtain data from the API response- Clutch-specific templating tokens in lieu of the standard Golang Template Action and Variable syntax
- Any of the Golang Template functions can be used in the template
Example Config:
...
services:
...
- name: clutch.service.db.postgres
...
- name: clutch.service.auditsink.slack
typed_config:
"@type": types.google.com/clutch.config.service.auditsink.slack.v1.SlackConfig
token: <token>
channel: <channel>
filter:
rules:
- field: SERVICE
text: clutch.k8s.v1.K8sAPI
overrides:
- full_method: /clutch.k8s.v1.K8sAPI/ResizeHPA
- message: |
*Min size*: [[.Request.sizing.min]]
*Max size*: [[.Request.sizing.max]]