Case Study
Clutch was designed and built at Lyft to solve real problems in the engineering organization.
As an organization grows in terms of headcount, product, or both, the complexity of the tech stack will increase in kind. A rich tech stack requires a large set of tools and heuristics to operate safely. Over time, seemingly straightforward tasks become difficult to perform as engineers need an increasing amount of information and tooling to safely apply changes.

The Most Common Alert at Lyft
my-service / Machine stats (my-service-cluster-a) / CPU / High CPU
When work on Clutch began in 2019, pages for high CPU on one or more instances in a cluster accounted for over 20% of all alerts. This is despite having autoscaling enabled on nearly all clusters at Lyft.
The most common causes of this alert, roughly ordered were:
- A single bad virtual machine in a cluster
- Increased load due to an event or a competitor outage (i.e. a scenario difficult to account for in normal autoscaling policy tuning)
- Code deployed to service
- Code deployed to an upstream or downstream service dependency
- Configuration change
The most common courses of remediation were:
- Terminate the misbehaving instance
- Manually increase the size of a cluster
- Shed load by raising polling intervals in the mobile app
Mitigation (before)
In the event that the cluster required a resize, developers had three main options to apply the change.
GitOps
Lyft is all-in on infrastructure-as-code. However, resizing a cluster during an incident via GitOps is a painful experience.
In our implementation of GitOps, applying orchestration changes requires a full deploy of a service to minimize the possibility of configuration drift. It can take 10 minutes or more for CI to run tests, launch a deploy pipeline, and enact the latest declaration. In the event that the first value was not enough, the engineer would have to repeat the process. This would drastically increase the time it takes to mitigate the issue.
In addition, the desired size of a cluster is not generally controlled by orchestration code. It's a dynamic value that changes in response to average CPU usage. Committing this value would reset it on every deploy regardless of current conditions. For this reason developers would simply use minimum to enforce the desired size during an incident. Sometimes they would forget to revert their change after the incident was over costing thousands of dollars in unnecessary cloud resource usage.
CLI
aws-cli does not return any output unless an error occurs. The interface is also terse and error prone.
Developers often avoided the CLI due to the friction of performing 2FA flows on the command line, in addition to the usability and lack of positive feedback.
$ aws-okta exec elevated-role -- aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name my-auto-scaling-group \
--min-size 1 --max-size 3
$
UI
The console presents a large amount of functionality and information needed to perform a task which slows down operations and increases cognitive load.
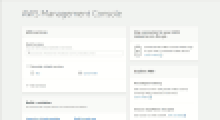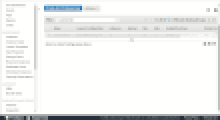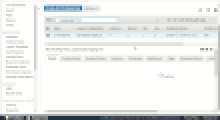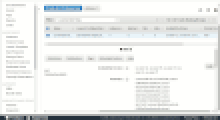
Mitigation (after)
Preventing Accidents
Next, we added rules to validate actions and prevent accidents that had occurred before with legacy tools.
- Don't allow scaling down more than
50%at a time. - Don't allow scaling to
0.
Auditing
By adding auditing stats and Slack logs, we could easily see which services were using the tool. One service we found was relying on the tool too frequently and we were able to tune their autoscaling policy so the service could autoscale correctly without manual intervention.

Results
Within a month of launching, all users had switched from using the old tools to Clutch as a matter of preference.
Having all of the workflow usage data on hand in Slack has also made pain points more obvious to our platform teams. This has resulted in improvements to capacity planning and autoscaling, to reduce dependence on the workflow.
Users have contributed more workflows and tools as a result of user preference and the extensible and maintainable aspects of Clutch.
Testimonials
- "The usability is super awesome and improves quality of life for engineers at Lyft."
- "Reduces a lot of stress during incident management."
- "A++++ would recommend. This is such a useful tool!"
- "I'm so happy that this exists because otherwise I would still waiting on the tab to load in the old console."
Planned Enhancements
Specific to the service resize workflow, we plan to:
- Incorporate other relevant information such as CPU usage into the detail display.
- Automatically predict the correct value based on available stats such as CPU usage.
- Take advantage of Clutch's resource-level authorization to limit service resizing to owners of that service. Implementing this with the vendor IAM primitives is very difficult.
- Optionally apply new values to the orchestration definition.
General Tooling Observations
At Lyft, we observed the following recurring issues with the available tooling for managing infrastructure:
- Vendor tools are slow due to lack of specialization, requiring unnecessary steps to perform an action or increasing latency by presenting unnecessary information.
- Vendor tools have little to no concept of safety or implementation of guardrails because the safety of an action is highly dependent on the design of the overall system. An operator may perform an action that seems innocuous but in turn degrades the system. This could be due to lack of familiarity with the system, a typo, etc.
- Operators are inherently unfamiliar with tools due to infrequent use, changing system topology, and gaps in onboarding and continuous education.
- Diagnostic information is spread across multiple systems, delaying the correct remediation decision. Operators may also not understand or know which information or heuristics are needed to gauge the risk of performing an action.
- Operators are given broad permissions for certain systems so they can diagnose and fix an endless variety of problems without requiring time-sensitive escalation and collaboration.
- Tools may not have a useful access control model, in particular a model that is compatible with the structure of the organization and the granularity and roles within teams.
- Tools that have access control were not originally designed with it in mind, displaying a cryptic error or only displaying an error after the operator has spent significant time and effort preparing to execute an action.
- Remediation is not automated because there exists no scalable and maintainable method of doing so.
These issues directly result in:
- Elevated mean time to repair (MTTR).
- Unintended or exacerbated outages due to erroneous operator action.
- Engineering productivity loss due to on-call burnout.
Resolving these issues with existing tools are a focus as we build out more functionality in Clutch.