Architecture
Clutch is designed at its core to be extensible and reprogrammable.
Every organization is different. Teams, services, databases, and configurations come in all shapes and sizes and interactions with those systems can have just as much variation.
Clutch allows developers to easily leverage existing interfaces to create their own extensions or customizations without having to fork or rewrite significant portions of the code.
Having a clear mental model of Clutch's abstractions and components will make it easier to configure, operate, and develop features for your organization.
Design Goals
Clutch is primarily geared towards the development of Workflows. Workflows usually start with locating a resource and then displaying information about it with the option to modify its configuration in a guided fashion. The architecture supports this by providing abstractions and primitives that allow developers to focus fully on the intent of their code and less on its structure.
"Single pane of glass" applications are inherently fragile. Clutch's component architecture supports feature development in a maintainable and extensible way. Of course, Clutch still allows using components piecemeal to implement new features that don't strictly adhere to the workflow archetype.
API Definitions
Development of most features in Clutch starts with an API definition. All Clutch APIs are written in Google's proto3 format. See the Protocol Buffer's Language Guide.
Protobuf has a rich tooling ecosystem. Clutch uses protobuf tooling for:
- JSON <-> gRPC transcoding from a single API definition
- Server API stub implementations and API objects
- Frontend API objects
- Input validation code from annotations
- Auditing and authorization configuration for each API endpoint from annotations
For more information on APIs in Clutch visit the API Development docs.
Backend
Gateway
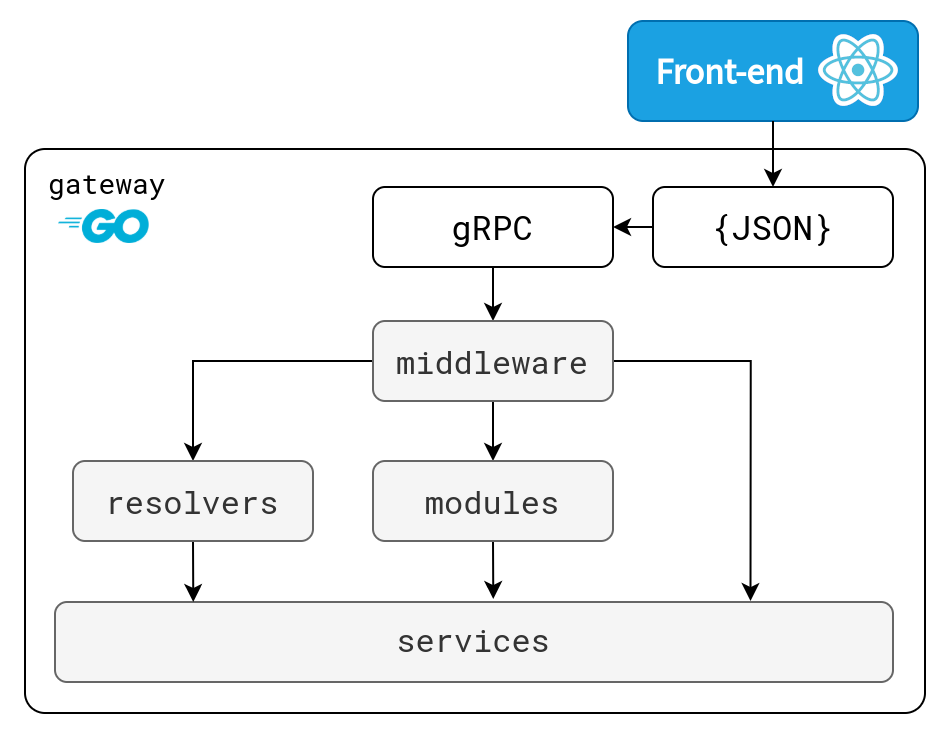
gateway is responsible for reading the configuration file, instantiating the specified components, and placing them in a component registry for runtime usage.
The gateway also manages the JSON/gRPC server and listeners, making use of grpc-ecosystem/grpc-gateway.
When Clutch starts, gateway will instantiate components in the following order:
service— Clients for external APIs or databases.resolver— Resource search and server-side form generation for resource search.middleware— Request and response inspection for the purposes of logging, auditing, authentication, etc.module— Implementations of stubs generated from API definitions.
The overall component instantiation order is important because service components are dependencies in resolver, middleware, and module components. service components may also depend on each other.
Services
service components provide a common interface for other components to interact with other services and databases including:
- Cloud providers
- Time-series databases
- Actual databases
- Third-party services
- Configuration stores
Examples of other types of components interacting with services:
middleware: authentication middleware uses aserviceto exchange tokens with an OpenID Connect provider.module: the AWS module uses aserviceto interact with cloud resources via the AWS APIs.resolver: the AWS resolver uses aserviceto locate resources using Amazon APIs.service: the auditservicefans out to audit sinks which are also defined as aservice.
Services are always exposed as an interface, so they can easily be replaced with a modified or fully custom implementation.
Resolvers
resolver turns ID resolution logic such as resource ID normalization into a pluggable component.
Most workflows start with the need to locate one or more resources. Resources such as nodes, services, and databases can be found in any organization, but are rarely referred to in the same way or by the same common name. This can be due to team or service structure, migration from another system, legacy systems, individual requirements, or many other reasons.
In addition to locating resources, resolvers also describe how they locate resources by producing schemas for user input. These schemas can be rendered by the frontend or other clients dynamically so that workflows can remain agnostic to resource location. See Frontend Resolver Component for more information.
have and want
All resolver APIs are in terms of have and want. For example:
havean IP address,wanta virtual machine IDhavean application name and a SHA,wanta virtual machine IDhavea user ID,wanta list of services the user owns
Free-form Search
Resolvers allow users to search for resources across all haves for a want with a simple string.
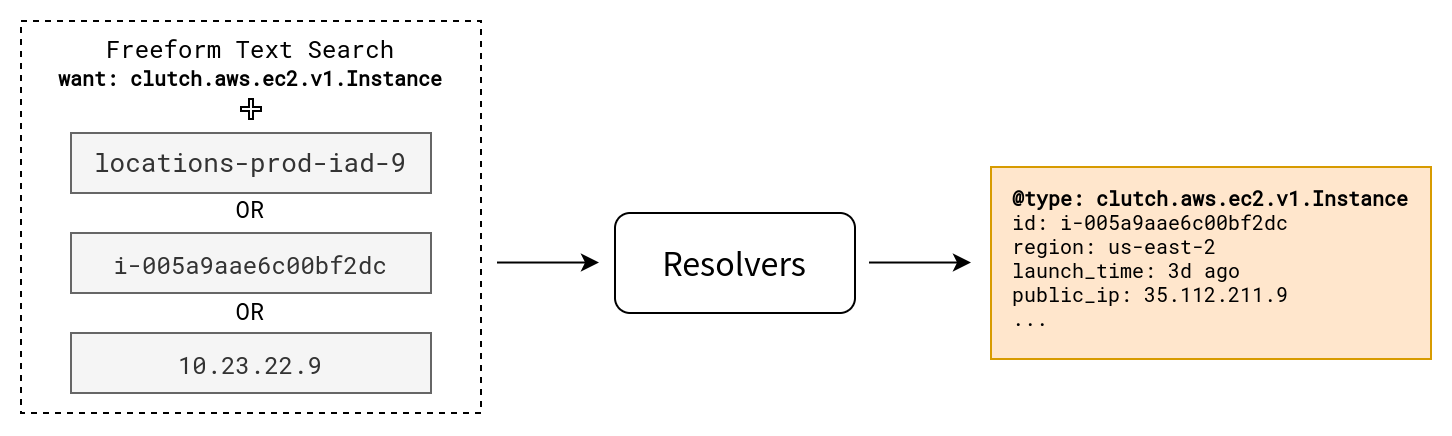
Structured Queries
The resolver will provide a structured schema for a wanted type. The process is as follows:
- Client requests schemas for
wanted type. - Server returns any registered
haveschemas for thewanted type. - Client submits a filled in
haveschema with thewanted type. - Server returns found
havetype objects.
Extending Resolvers
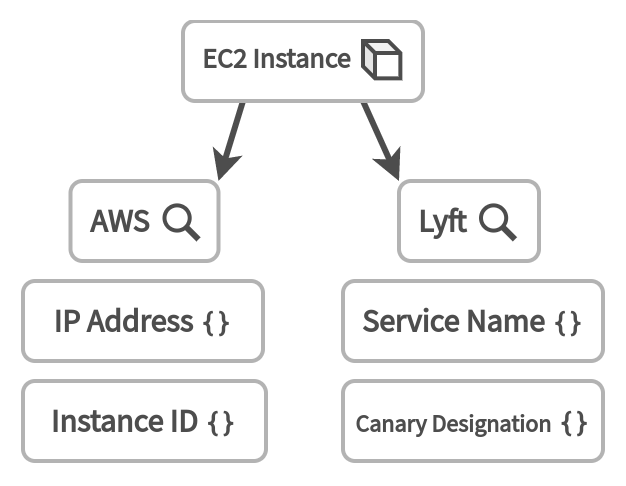
Clutch allows you to plug-in additional have types for want types based on the organization's vernacular. For example, if the organzation where Clutch is deployed haves the concept of a canary and wants a virtual machine ID that corresponds to it, the entire logic for querying resources does not have to be forked or rewritten.
In the diagram below, Lyft has registered its own additional resolver for locating EC2 instances. While instances are sometimes located by ID, it's more common to find an instance that is a member of a given service, or a canary member of a cluster. Those designations look different at Lyft than they would at any other company, so there is an internal resolver schema plugged in that provides these additional lookup capabilities.
Middleware
middleware is responsible for inspecting incoming requests and the outgoing response for the purposes of observability, authentication, authorization, and more. This allows APIs to be implemented with less boilerplate. The result is more standardized and consistent use of server-side primitives, with little to no burden on the developer to incorporate them.
Sometimes middleware will need to talk to an external system, such as an authentication provider. It is considered best practice to handle these interactions via a service interface. The main benefit of this is allowing APIs whose needs are not met by the middleware to make additional calls to external services.
Within middleware, it is also possible to read API annotations specific to the endpoint or request/response objects.
Modules
Modules are implementations of the stubs generated from an API definition. Modules can be accessed via gRPC or JSON via the gateway's listener.
Frontend
The frontend consists of a few components to make workflow development easier. They can be used in combination for most simple workflows, or separately for more advanced features.
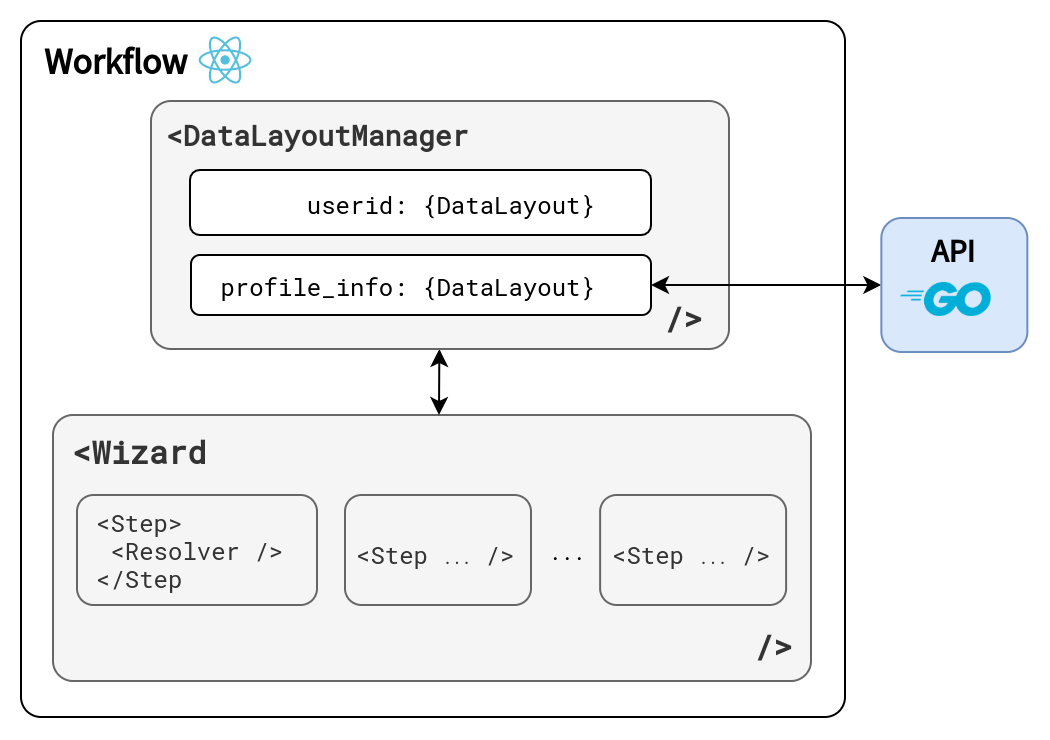
Data Layout
Clutch provides the data-layout package for workflow-local state management.
The data layout component consists of two main pieces, layouts and the layout manager. The layout specifies whether data hydrates from an external API or user input. If the data comes from an external API, the data layout will also contain the loading and error state for the data.
Wizard
The wizard component manages the progression and state of each workflow, giving users a clear depiction of where they are in the flow.
The wizard takes steps of the workflow as children. The wizard also injects the data layout manager's context so each step can access any data-layout.
Resolver
As mentioned in Backend Resolvers above, the resolver API allows for users to look up resources in one of two ways, either using a query resolver or a structured schema.
Using the schemas returned by the API, the frontend has a built-in component to render schemas for both free-form and structured search from a single line of code.
<Resolver type={"clutch.aws.ec2.v1.Instance"} />
results in the rendered form below